Mercury 2 and the Rise of Real-time Subagents
How Inception's diffusion LLMs power fast, parallel agent workflows in production at Augment Code

Inception Team
The future of AI systems is not a single agent doing everything. It is multiple agents working together.
That is already happening in coding. What looks like one coding agent from the outside is actually a system made up of specialized components. One part plans, another explores the codebase, another writes the implementation, and another compresses context so the session can continue.
This is not just an implementation detail. It is becoming the core architecture of agentic systems. According to inference platforms like Baseten, customers run 7-10 models in production for targeted tasks, each powering a different part of the pipeline.

Why multi-agent systems win
There are structural, unavoidable tradeoffs between speed, quality, and cost for LLMs.
The model you want for the hardest reasoning step is often not the model you want for every supporting operation. If you use the most expensive model everywhere, latency and cost become a problem. If you use the cheapest model everywhere, quality breaks at critical moments.
The optimized system picks the right tool for the right problem.
That is why multi-agent systems are so powerful. They let developers route different tasks to different models depending on what each step actually requires. Deep reasoning can go to one model. High-frequency utility tasks can go to another. The result is a system that is better overall.
Compaction is the clearest proof point
In a long coding session, context fills up multiple times. The agent has explored files, made decisions, debugged issues, and accumulated a large amount of state. At some point, that context becomes too large to carry forward. The system has three choices: fail, truncate blindly, or compress intelligently.
Compaction is the third option. A subagent reads the long interaction history and turns it into a compact structured summary that preserves the decisions, relevant files, unresolved issues, and next steps. That summary becomes the new working state for the main agent. This is harder than it sounds. Compaction requires long-context understanding, fidelity and structured output generation, and low latency all at once.
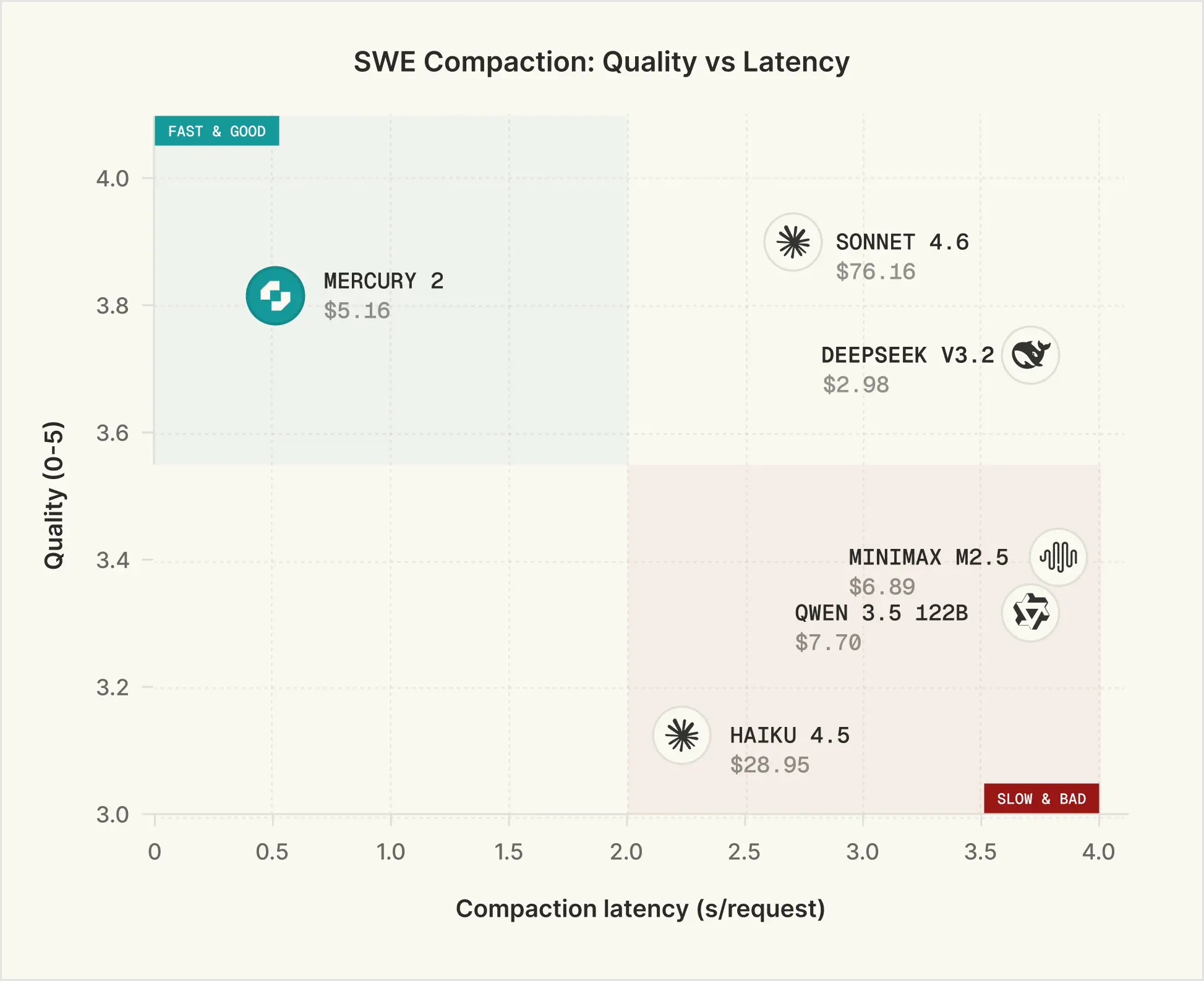
To evaluate the quality of context compaction of different models, we follow the methodology proposed here. We randomly sample 250 multi-turn agentic trajectories from each of SWE-chat and SWE-smith and use an LLM to generate 4 probe questions about these traces, covering specific factual recall, decisions made, artifact file tracking, and logical continuation, along with their corresponding ground truth answers. Candidate compaction models are then used to summarize the trajectories, with explicit prompting to preserve the elements above. An LLM is provided the summary and answers the 4 probe questions, which are scored against the ground truths on a 0–5 scale.
We run this eval across multiple models and measure compaction latency as the average end-to-end latency per request. Mercury 2 is the only model in the "Fast & Good" quadrant - roughly 5x faster than Sonnet 4.6 while matching it on quality. On the speed-quality-cost tradeoff, Mercury 2 doesn't compromise.
Augment Code’s enterprise coding agents, in production
Augment Code, creator of Auggie & Cosmos, is an AI-powered operating system for the entire software development lifecycle. Enterprise engineering teams use it to seamlessly coordinate their tools, agents, and shared memory, ensuring that every new AI workflow makes the whole organization smarter.
"To build the best AI coding agent on the market, you have to rethink standard architecture. The industry consensus for context compaction is to use the user's primary model, like Opus 4.7, to summarize data and preserve the KV cache. We took a counter-intuitive bet. We decoupled summarization entirely, offloading it to Mercury 2 as a dedicated subagent.
Because Mercury 2 delivers the perfect threshold of intelligence at lightning speeds, the equation heavily works in our favor. We cut summarization latency by 82% (down from ~150 seconds) and dropped costs by 90%. Whether it is handling complex context compaction, driving our Prism model router, or returning tool-search summaries in under a second, Mercury 2 is the highly efficient engine powering our most critical workflows."
Ankur Rustagi & John Mu, Members of Technical Staff at Augment Code
Here is how Augment Code leverages Mercury 2 in production:
Context Compaction: Mercury 2 drives Augment’s context compaction with remarkable efficiency. Compared to previous models (like Opus 4.7), switching to Mercury 2 led to an 82% drop in latency and a 90% reduction in cost, all while maintaining the exact same compaction quality.
Intelligent Model Routing: Serving as the high-speed planner for their Prism router, Mercury 2 helps direct tasks to the most efficient mode. Prism’s dynamic routing reduces total LLM spend by 30% without sacrificing code quality.
Lightning Fast Tool Search: Augment uses Mercury 2 to generate Model Context Protocol (MCP) server’s tool summaries. It acts as the engine behind their "find-tool," instantly matching the right tool to the task at hand. Mercury 2 returns these summaries in under a second, speed that is absolutely critical for preserving a seamless user experience while avoiding the bloat of keeping every tool in the active context window.
Beyond coding, this is where agentic systems are going
The same pattern extends well beyond coding. Customer support systems will route across specialized agents for triage, retrieval, resolution, escalation, and quality control. Workflow automation systems will use different agents for intake, routing, execution, exception handling, and auditability.
In all of these cases, many of the most important calls in the system do not require the very highest level of intelligence. They require something else: strong enough quality, very high speed, and low cost at scale. That is exactly the subagent layer. These are the repeated utility calls that keep the overall system moving: summarizing state, routing tasks, searching context, preparing handoffs, checking outputs, and structuring information for the next step.
This is where Mercury 2 matters most. Mercury 2 is a diffusion-based LLM, and pushes the Pareto frontier of speed, quality, and cost. That means developers do not have to trade away quality to get latency and cost down, and they do not have to accept slow, expensive utility calls just to preserve reliability. For subagents that do not require the highest level of intelligence, Mercury 2 is the best solution because it moves that frontier outward.
Get started
Mercury 2 is OpenAI API compatible. Drop it into your existing stack. No rewrites required.
If you're running an enterprise evaluation, we'll partner with you on workload fit, eval design, and performance validation under your expected serving constraints. Reach out at sales@inceptionlabs.ai.