

Today we're introducing Mercury Edit 2: a purpose-built diffusion LLM (dLLM) for the most latency-sensitive component of modern development workflows: next-edit prediction. This model upgrades our previous next-edit model and complements our existing auto-complete endpoint.
Using your recent edits and codebase context, Mercury Edit 2 predicts what you’ll change next. Because Mercury Edit 2 uses diffusion to generate tokens in parallel, predictions arrive fast enough to feel like part of your own thinking. Just Tab to accept.
How we trained our model
To train this model, we carefully curated a high quality dataset of edits across a broad range of languages and scenarios. These examples taught our model how to interpret a history of edits and codebase context into a targeted next edit suggestion. While powerful, we found that the model could be overzealous in the frequency and length of its edits, distracting the user.
To combat this, we gather a high quality human preference dataset by recording the explicit feedback (accepting vs rejecting an edit) that our model receives. Using this dataset, we leverage an unpaired reinforcement learning method called KTO to align our model with human preferences. We find that this step is important for increasing the utility of our model.
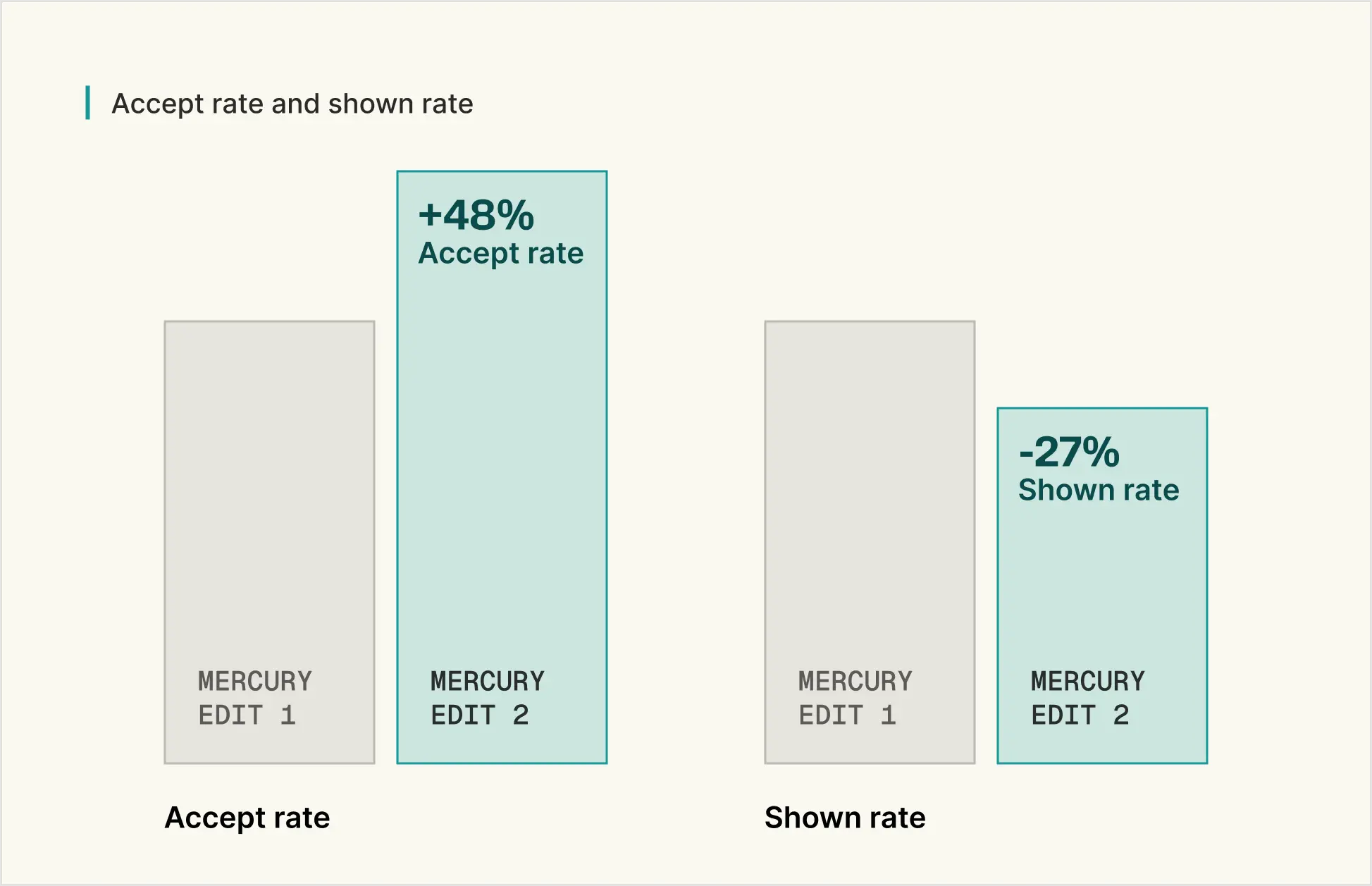
The results are clear. Our new model’s edits are accepted 48% more often, emphasizing the value of this improvement. It is also 27% more selective in the edits it displays, leading to more targeted and less distracting edits.
How we compare
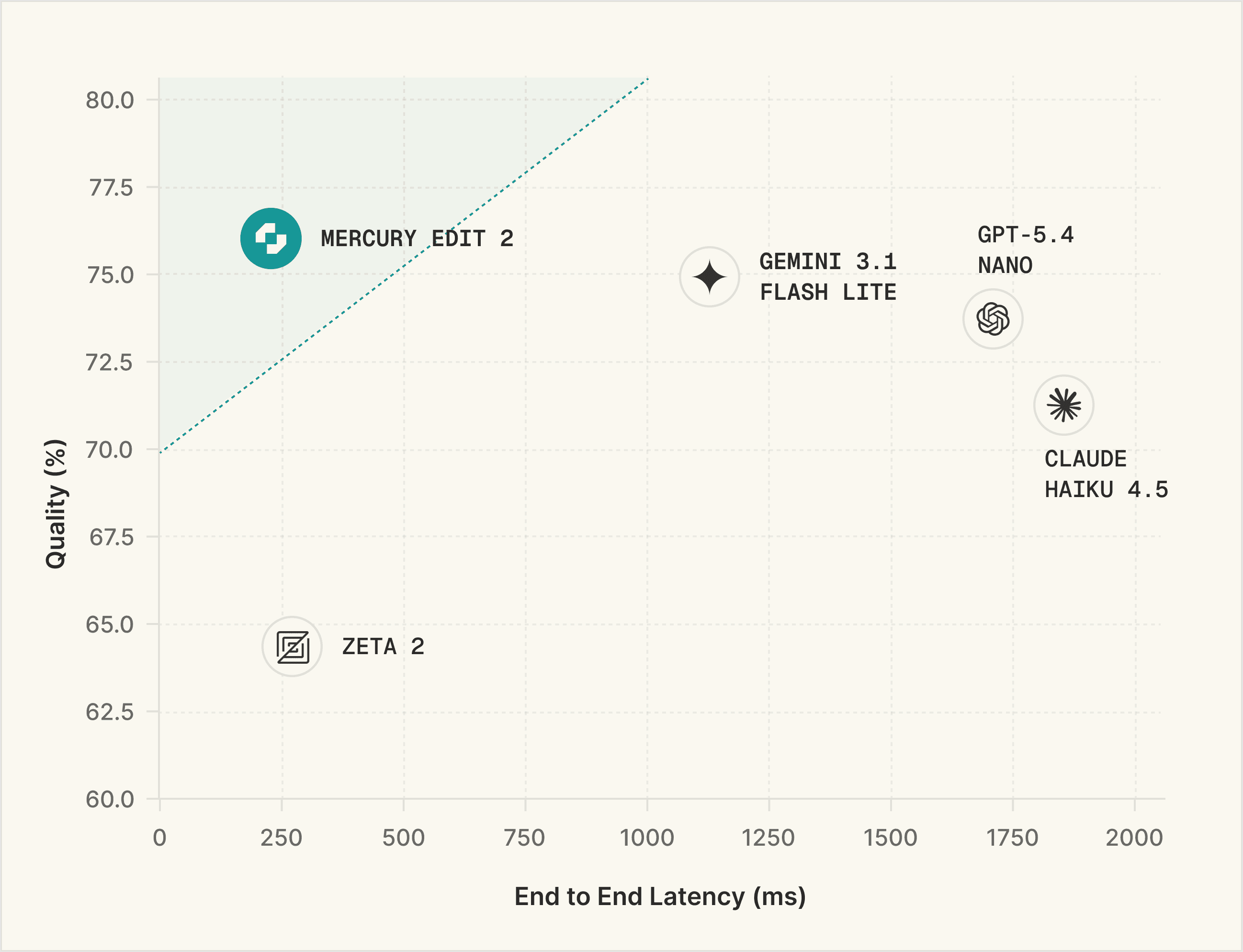
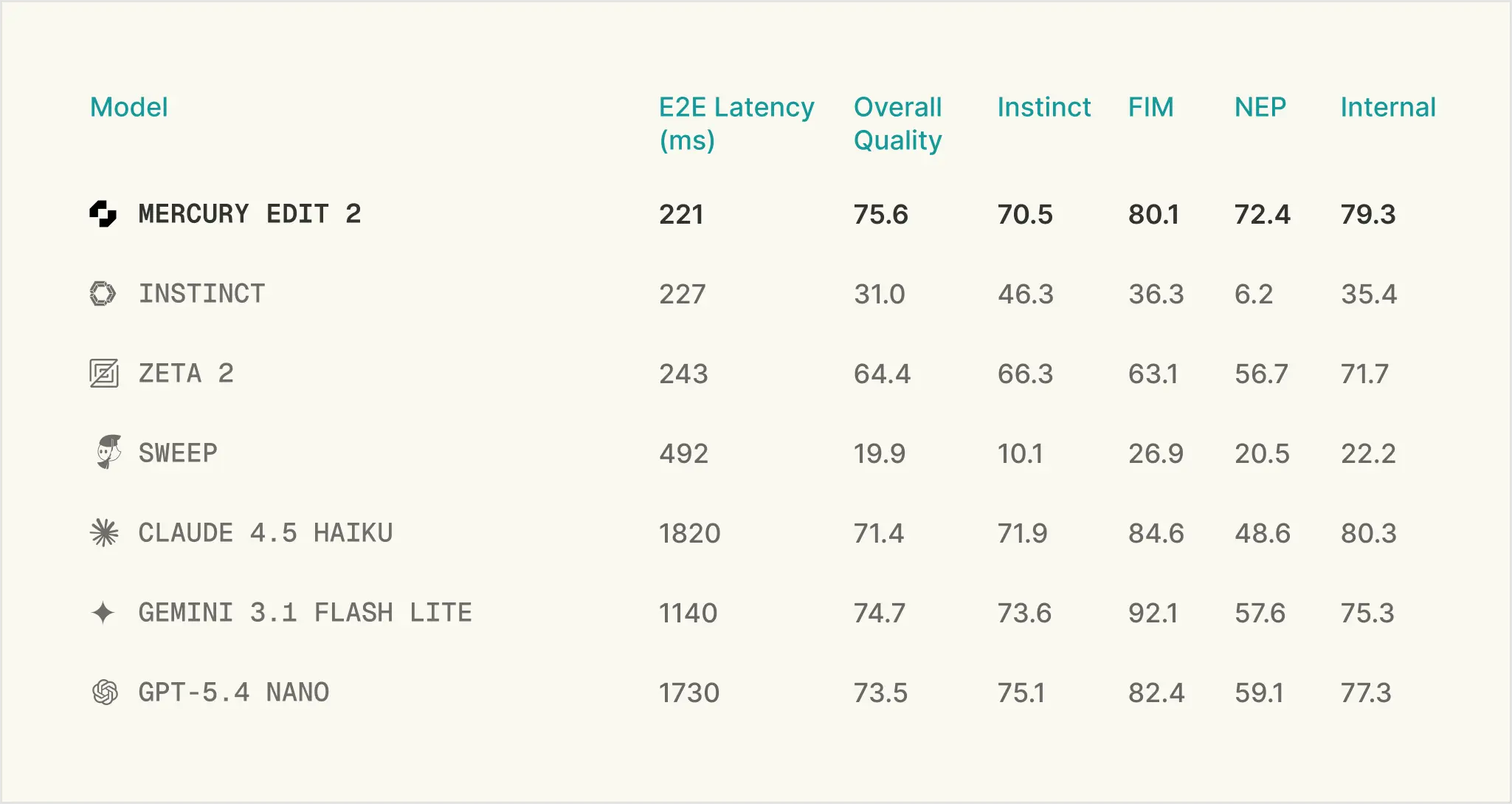
Next-edit suggestions must be both high quality and fast. To measure quality, we benchmark our model on three open-sourced (Instinct, Fill-in-the-middle (FIM), and Next-edit Prediction (NEP)) and one internal next-edit benchmarks. FIM validates edits by running test cases against the modified code. The other three benchmarks utilize an LLM-as-a-judge to determine correctness based on the similarity between the proposed edit and a human-written gold-standard answer. This suite of benchmarks covers a variety of edit scenarios, like line completion, variable renaming, refactoring, feature implementation, and many more. Our final quality measurement is an average of the four. We benchmark speed by measuring the end to end latency on a set of representative requests. For comparison, we also benchmark several custom next-edit models and speed-optimized frontier models. We find that Mercury Edit 2 offers both superior quality and speed to alternatives.
Get started
"We built Zed's edit prediction system to be provider-agnostic because developers should choose what works for them. Mercury Edit 2 brings a diffusion-based approach to the table -- it's a meaningfully different way to generate edit predictions, and we're glad to offer it alongside other providers."
Max Brunsfeld, Co-Founder, Zed
Mercury Edit 2 is available now on the Inception Platform.
Mercury Edit 2 is priced at $0.25 / 1M input tokens and $0.75 / 1M output tokens, with cached input at $0.025 / 1M tokens. Every new account created on the Inception API Platform is automatically granted 10 million FREE tokens.
In addition, Zed users can unlock 1 free month of Mercury Edit 2 Edit suggestions with this API key: sk_ae471146ea60fc117c131b574b00ba96.
Configure Mercury Edit 2 with Zed →
Building developer tools and want to integrate Mercury Edit 2? Reach out at hello@inceptionlabs.ai. Join our Discord for support, feedback, and early access to what's next.