

The fastest reasoning LLM, powered by diffusion
Today, we're introducing Mercury 2 — the world's fastest reasoning language model, built to make production AI feel instant.
Why speed matters more now
Production AI isn't one prompt and one answer anymore. It's loops: agents, retrieval pipelines, and extraction jobs running in the background at volume. In loops, latency doesn’t show up once. It compounds across every step, every user, every retry.
Yet current LLMs still share the same bottleneck: autoregressive, sequential decoding. One token at a time, left to right.
A new foundation: Diffusion for real-time reasoning
Mercury 2 doesn't decode sequentially. It generates responses through parallel refinement, producing multiple tokens simultaneously and converging over a small number of steps. Less typewriter, more editor revising a full draft at once. The result: >5x faster generation with a fundamentally different speed curve.
That speed advantage also changes the reasoning trade-off. Today, higher intelligence means more test-time compute — longer chains, more samples, more retries — bought at the direct expense of latency and cost. Diffusion-based reasoning gets you reasoning-grade quality inside real-time latency budgets.
Mercury 2 at a glance
Mercury 2 shifts the quality-speed curve for production deployments:
Speed: 1,009 tokens/sec on NVIDIA Blackwell GPUs
Price: $0.25/1M input tokens · $0.75/1M output tokens
Quality: competitive with leading speed-optimized models
Features: tunable reasoning · 128K context · native tool use · schema-aligned JSON output
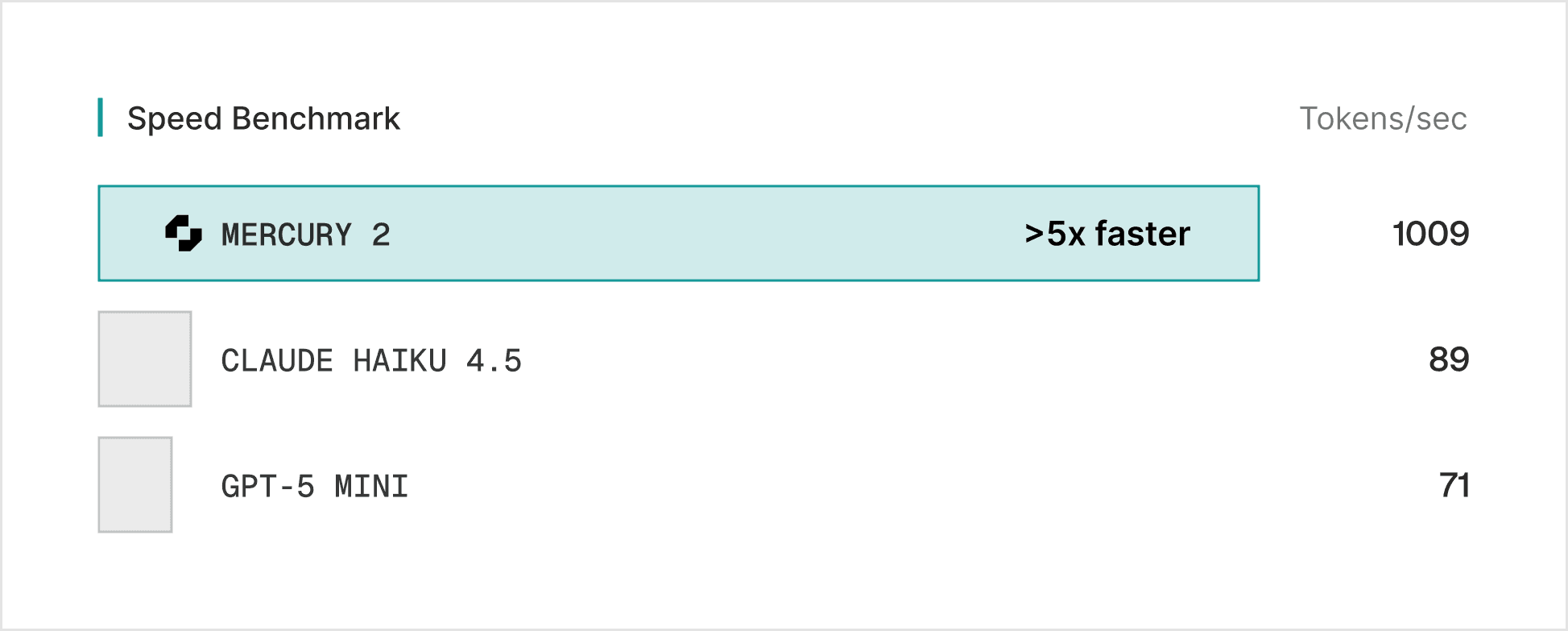
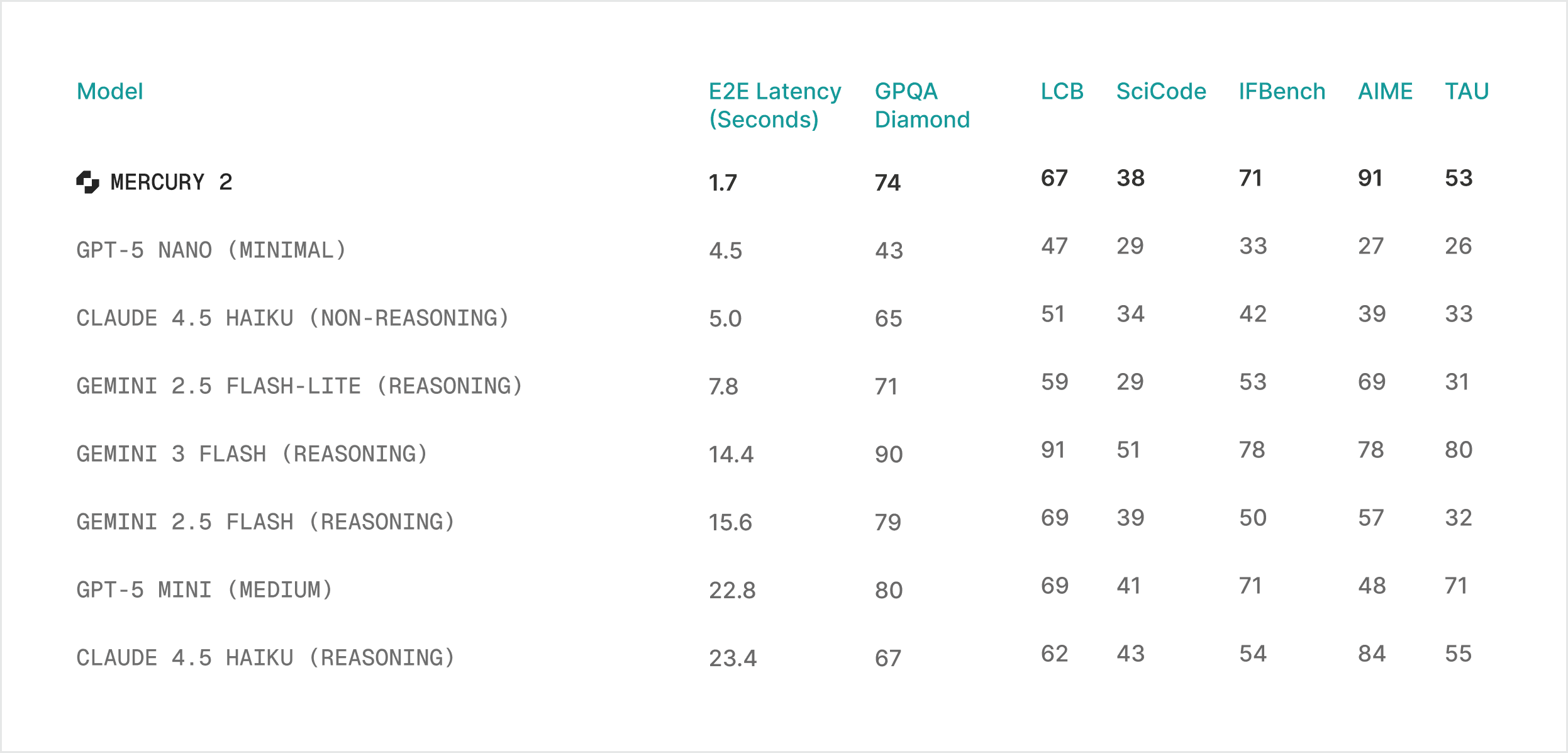
We optimize for speed users actually feel: responsiveness in the moments users experience - p95 latency under high concurrency, consistent turn-to-turn behavior, and stable throughput when systems get busy.
“Inception’s Mercury 2 demonstrates what’s possible when new model architecture meets NVIDIA AI infrastructure. Surpassing 1,000 tokens per second on NVIDIA GPUs underscores the performance, scalability, and versatility of our platform to power the full spectrum of AI workloads.”
Shruti Koparkar, Senior Manager of Product, Accelerated Computing Group at NVIDIA
What Mercury 2 unlocks in production
Mercury 2 excels in latency-sensitive applications where the user experience is non-negotiable.
1. Coding and editing
Autocomplete, next-edit suggestions, refactors, interactive code agents - workflows where the developer is in the loop and any pause breaks flow.
“Suggestions land fast enough to feel like part of your own thinking, not something you have to wait for.”
Max Brunsfeld, Co-Founder, Zed
2. Agentic loops
Agentic workflows chain dozens of inference calls per task. Cutting latency per call doesn't just save time, it changes how many steps you can afford to run, and how good the final output gets.
“We’re now leveraging the latest Mercury model to intelligently optimize campaign execution at scale. By surfacing insights and dynamically enhancing delivery in real time, we’re driving stronger performance, greater efficiency, and a more resilient, AI-powered advertising ecosystem. This advancement reinforces our commitment to autonomous advertising, where intelligent systems continuously refine execution to deliver measurable outcomes for our clients.”
Adrian Witas, SVP, Chief Architect, Viant
“We’ve been evaluating Mercury 2 because of its unparalleled latency and quality, especially valuable for real time transcript cleanup and interactive HCI applications. No other model has come close to the speed Mercury can provide!”
Sahaj Garg, CTO & Co-Founder, Wispr Flow
"Mercury 2 is at least twice as fast as GPT-5.2, which is a game changer for us."
Suchintan Singh, CTO & Co-Founder, Skyvern
3. Real-time voice and interaction
Voice interfaces have the tightest latency budget in AI. Mercury 2 makes reasoning-level quality viable within natural speech cadences.
“We build lifelike AI video avatars that hold real-time conversations with real people, so low latency isn't a nice-to-have, it's everything. Mercury 2 has been a big unlock in our voice stack: fast, consistent text generation that keeps the whole experience feeling natural and human.”
Max Sapo, CEO & Co-Founder, Happyverse AI
“Mercury 2 quality is excellent, and the model’s low latency enables more responsive voice agents.”
Oliver Silverstein, CEO & Co-Founder, OpenCall
4. Search and RAG pipelines
Multi-hop retrieval, reranking, and summarization latencies stack fast. Mercury 2 lets you add reasoning to the search loop without blowing your latency budget.
“Our partnership with Inception makes real-time AI for our search product practical. Every SearchBlox customer, across customer support, compliance, risk, analytics, and e-commerce, benefits from sub-second intelligence across all of their data.”
Timo Selvaraj, Chief Product Officer, SearchBlox
Get started
Mercury 2 is available now.
Mercury 2 is OpenAI API compatible. Drop into your existing stack - no rewrites required.
If you’re doing an enterprise evaluation, we’ll partner with you on workload fit, eval design, and performance validation under your expected serving constraints.