
Nov 18, 2025
Partnerships

A New Architecture for Language Generation
Traditional language models generate text sequentially, one token at a time. This creates an inherent bottleneck where each token must wait for all previous tokens to be generated. Mercury uses a diffusion-based architecture to generate multiple tokens in parallel, enabling dramatically faster inference. The result: Mercury runs up to 10x faster than comparable autoregressive models.
Performance: Speed & Quality
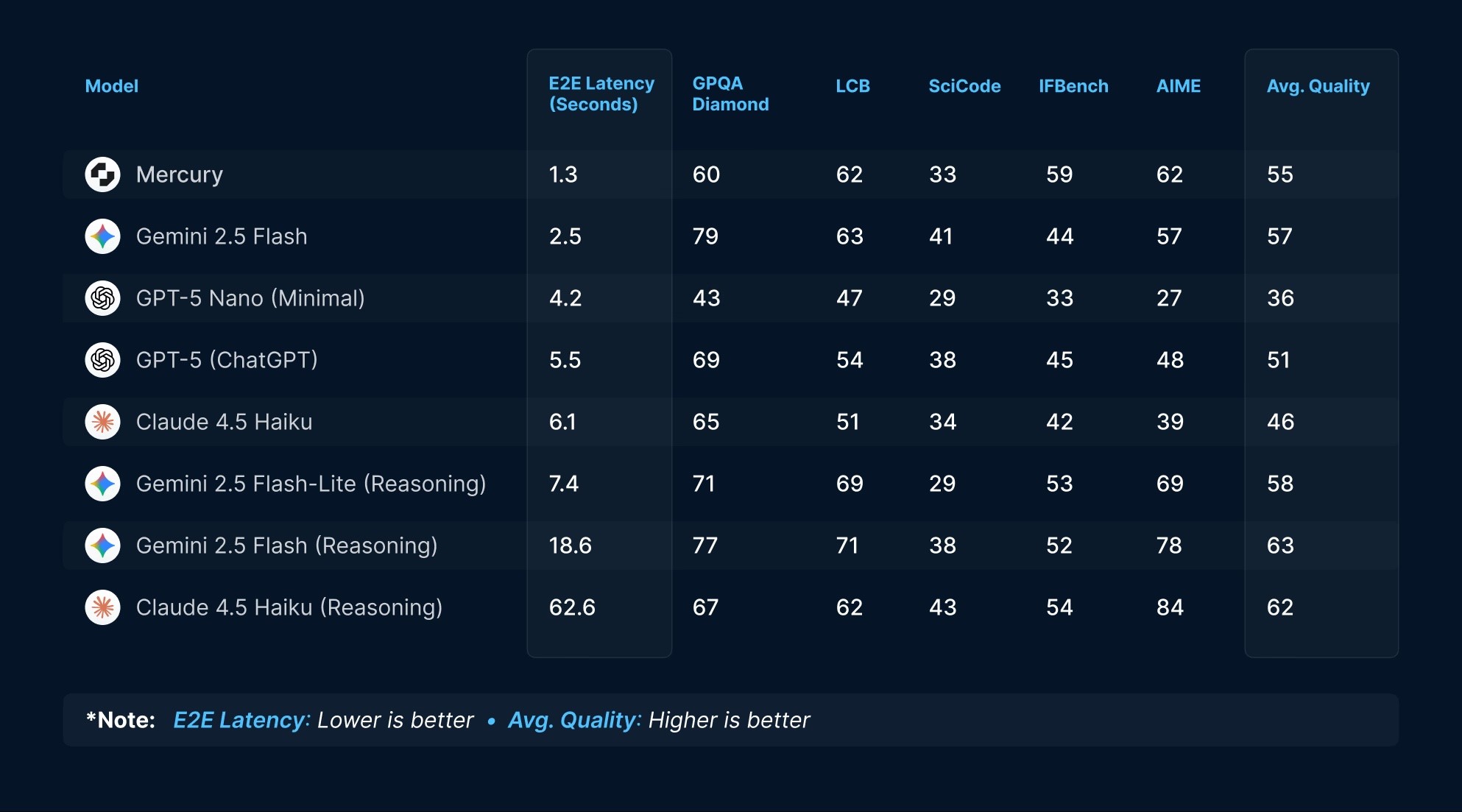
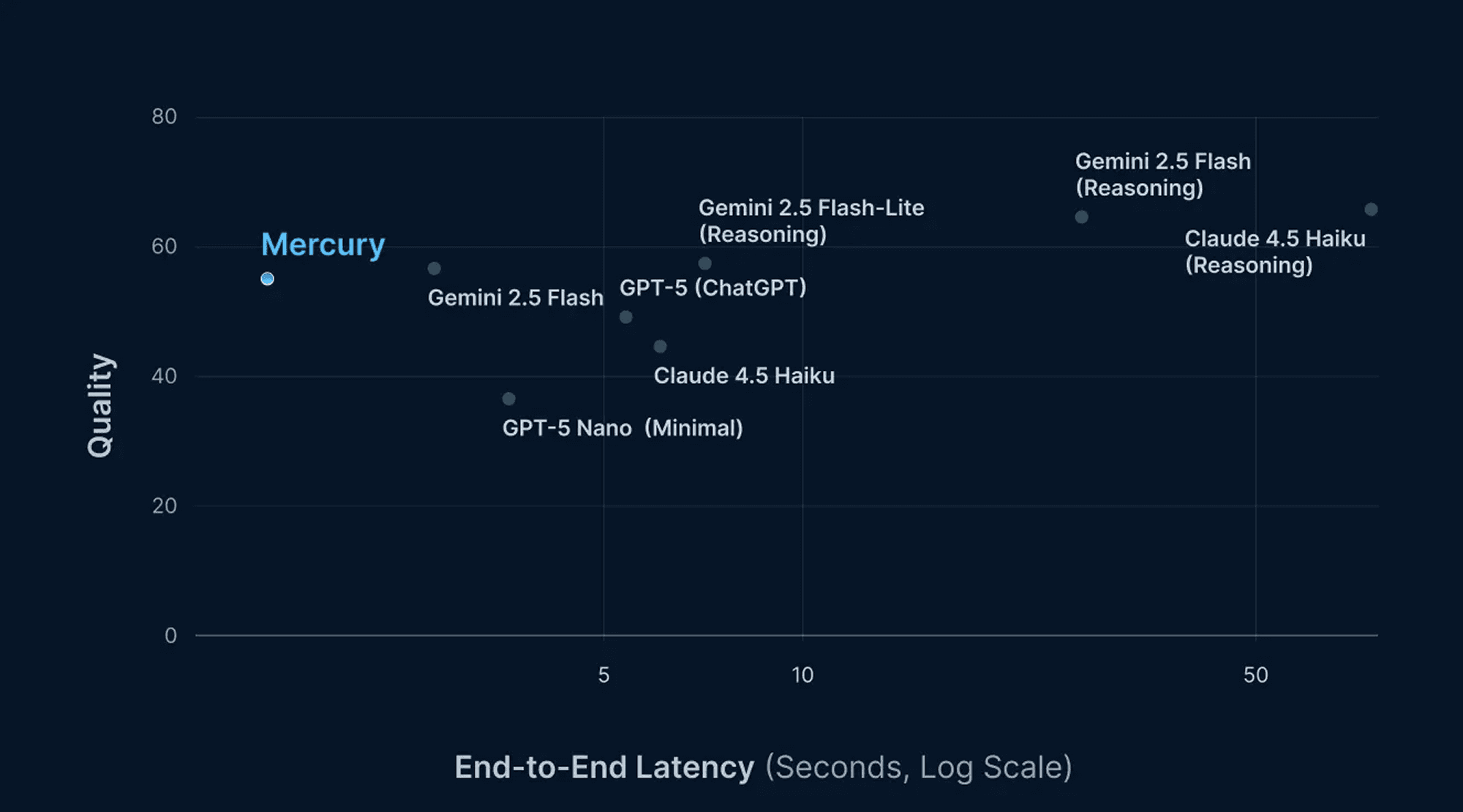
Mercury provides frontier quality with unparalleled speeds. Across knowledge, coding, instruction following, and mathematical benchmarks, Mercury performs on part with models like Gemini 2.5 Flash and Claude 4.5 Haiku, while running up to 10x faster.
Enterprise-Ready on Azure
Mercury on Azure AI Foundry is production-ready out of the box. It features a 128K token context window for processing large documents and maintaining extensive conversations, with native tool calling and structured output support using JSON schemas for building agentic workflows. The API is OpenAI-compatible, making integration with existing codebases seamless.
Azure AI Foundry provides enterprise-grade infrastructure including network isolation, data privacy guarantees ensuring your data stays in your Azure environment and is never used for training, Azure compliance standards including SOC2 and HIPAA, and comprehensive observability through Azure Monitor and Application Insights.
Real-World Use Cases
Mercury's speed-quality combination makes applications faster and more responsive:
Coding assistants: Stay in flow with responsive autocomplete, intelligent tab suggestions, fast chat responses, and more. Real-time voice agents: Engage naturally with AI for customer support, translation, and beyond.
Seamless enterprise workflows: Automate complex routing, analytics, and decision processes with ultra-responsive AI.
Rapid enterprise search: Instantly surface the right data from across your organization’s knowledge base.
Deploy on Azure AI Foundry
Mercury is available in US and Canada regions through Azure AI Foundry. Deployment is straightforward—provision your model endpoint and configure your infrastructure through Azure AI Foundry's unified catalog. Pricing consists of $5/hour for the Mercury software license, with compute costs billed separately through your Azure account based on the resources you provision.
Azure AI Foundry Integration:
Mercury integrates seamlessly with the broader Azure ecosystem. Deploy using Azure AI Foundry's model catalog, apply Azure AI Content Safety for content filtering, monitor performance and costs in real-time, manage access with Azure RBAC and managed identities, and build multi-model applications using Azure's agent framework.
Get Started in Three Steps
This section will be redone when the model is actually available in our private listing at least and we can test the workflow ourselves. This is a placeholder for now
Navigate to Azure AI Foundry Model Catalog at ai.azure.com
Search for "Mercury" and click Deploy to provision your endpoint.
Start building with your API endpoint—use the playground to test or integrate directly into your applications
Because Mercury is OpenAI-compatible, you can use existing OpenAI SDKs with minimal code changes:
The Future of Real-Time AI
The launch of Mercury on Azure AI Foundry marks a turning point for production AI applications. Developers no longer have to choose between speed and quality, between real-time responsiveness and frontier-model capabilities.
Deploy Mercury on Azure AI Foundry →
For detailed documentation, benchmarks, and integration guides, visit the Mercury model card in Azure AI Foundry.
Related Reading




