
Sawyer Birnbaum
Chief of Staff
In February, we announced Mercury Coder, the first commercial-scale diffusion large language model (dLLM), which provides developers with ultra-fast code generation. Today, we’re excited to announce that Mercury, our first general chat model, is available to support a wider range of text generation applications.
When benchmarked by Artificial Analysis, a leading third-party model evaluator, Mercury matches the performance of speed-optimized frontier models like GPT-4.1 Nano and Claude 3.5 Haiku while running over 7x faster.
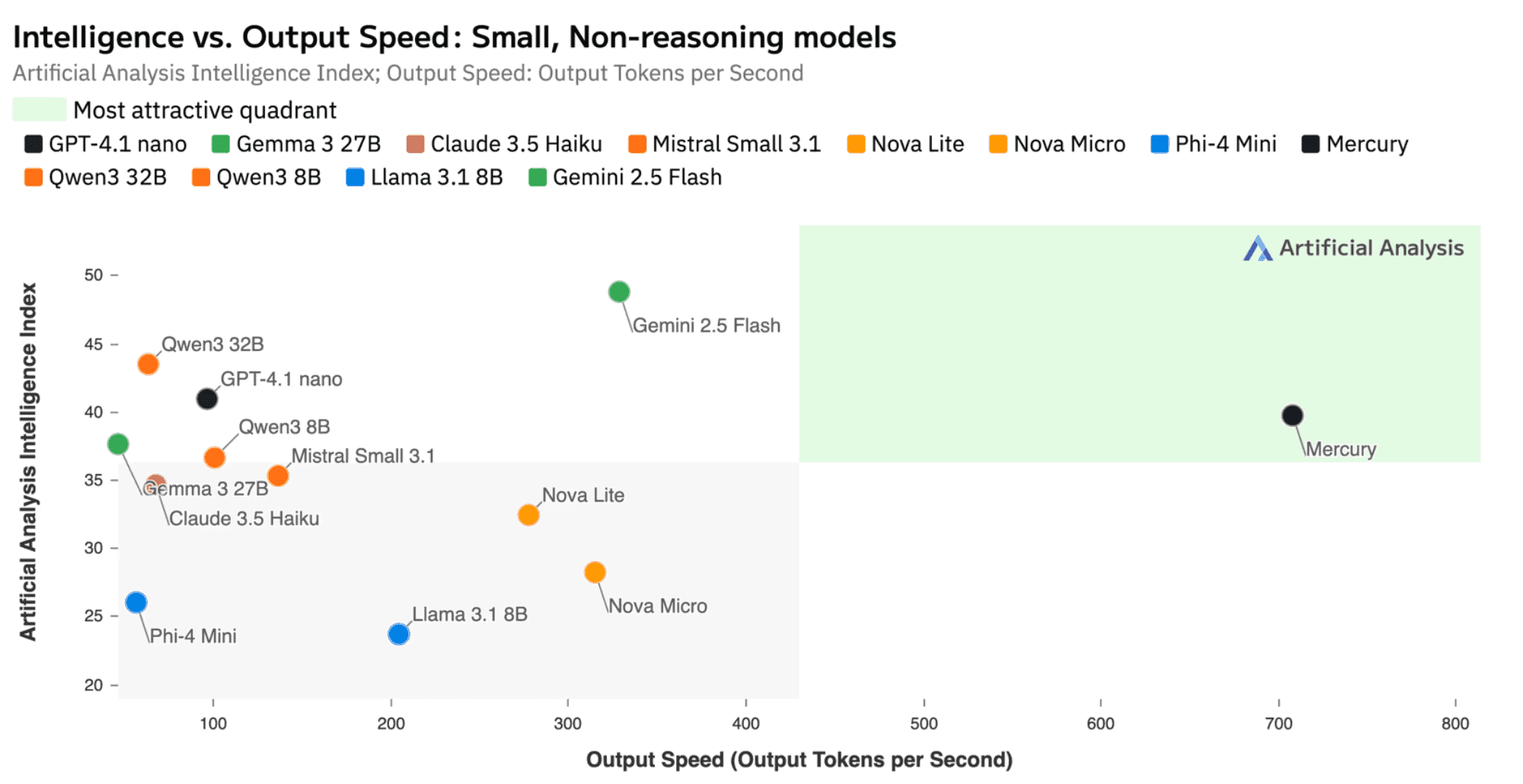
Mercury | GPT-4.1 Nano | Claude 3.5 Haiku | Gemini 2.5 Flash | Qwen 3 32B | Gemma 3 27B | Mistral Small 3.1 | Nova Lite | |
Throughput (tok/sec) | 708 | 96 | 67 | 329 | 63 | 46 | 136 | 277 |
MMLU-Pro | 69 | 66 | 63 | 78 | 73 | 67 | 66 | 59 |
GPQA Diamond | 51 | 51 | 41 | 59 | 54 | 43 | 45 | 43 |
Humanity's Last Exam | 3.4 | 3.9 | 3.5 | 5.0 | 4.3 | 4.7 | 4.8 | 4.7 |
LiveCodeBench | 23 | 33 | 31 | 41 | 29 | 14 | 20 | 17 |
SciCode | 18 | 26 | 27 | 23 | 28 | 21 | 27 | 14 |
HumanEval | 85 | 88 | 86 | 89 | 90 | 89 | 86 | 84 |
MATH-500 | 83 | 85 | 72 | 93 | 87 | 88 | 71 | 77 |
AIME 2024 | 30 | 24 | 3 | 43 | 30 | 25 | 9.0 | 11 |
As such, Mercury is the next step towards a diffusion-based future for language modeling, replacing the current generation of autoregressive models with extremely fast and powerful dLLMs.
Here are a few ways that early adopters are using Mercury.
Real-Time Voice
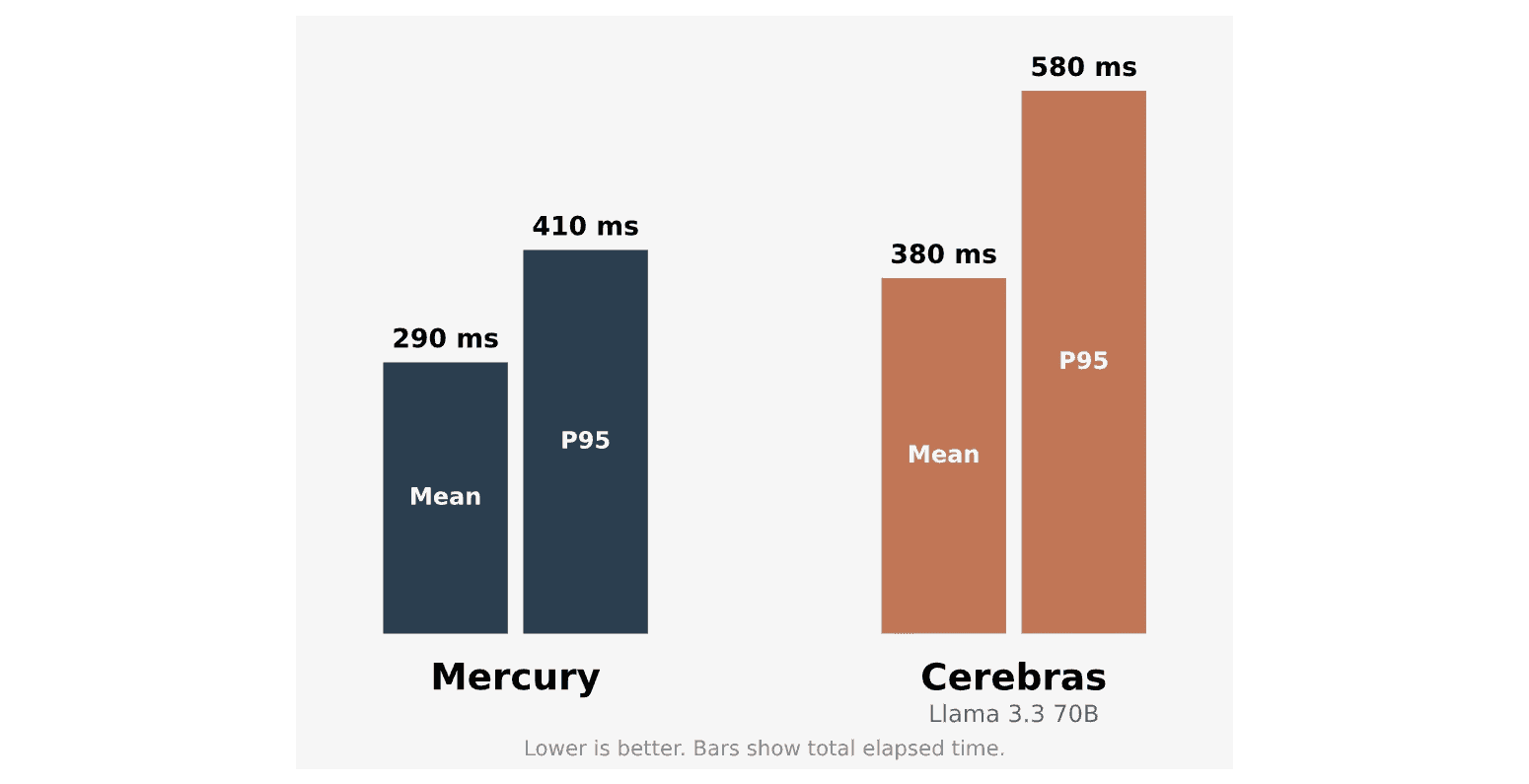
Mercury’s low latency enables it to power responsive voice applications, ranging from translation services to call center agents. The below plot shows the end-to-end latency of real-world voice agent prompts on Mercury compared with Llama 3.3 70B running on Cerebras. Although Mercury is running on standard NVIDIA GPUs, it provides significantly lower latency than Cerebras’s custom hardware.
Interactive Online Websites
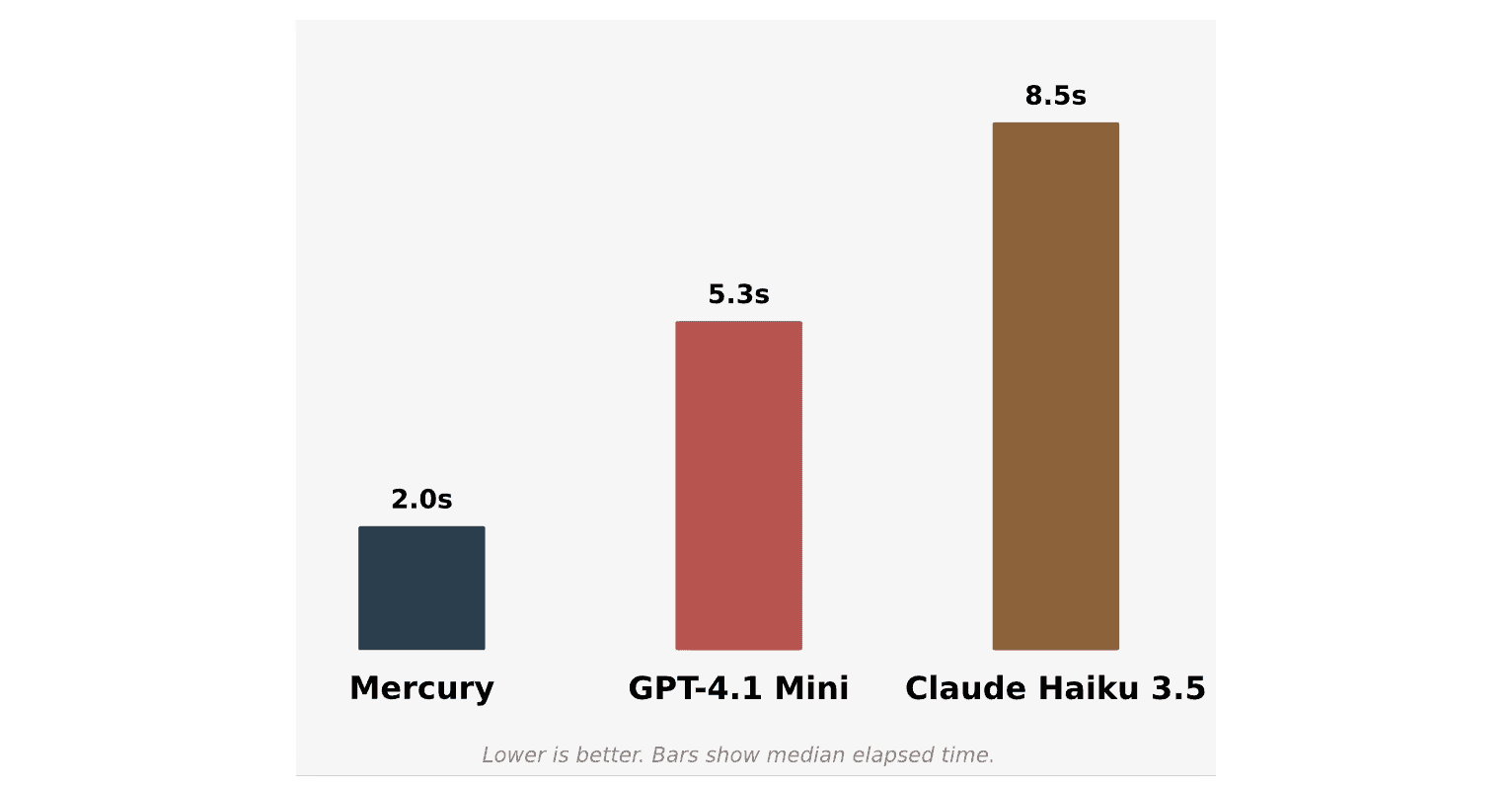
Mercury is the founding LLM partner for Microsoft’s NLWeb project. Announced at the CEO keynote at Microsoft's Build Conference, NLWeb allows publishers to easily create natural language interfaces on their websites, providing a hallucination-free experience. When combined with Mercury, NLWeb’s architecture enables lightning-fast, natural conversations grounded in real data. Compared with other speed-focused models like GPT-4.1 Mini and Claude 3.5 Haiku, Mercury runs far faster, ensuring a fluid user experience. Read more about how Mercury is supporting NLWeb here.
How to Use Mercury
Explore our playground
Connect via our API platform
Connect on OpenRouter
Connect on Models.dev
If you are an enterprise customer interested in Inception's dLLM technology, please reach out to us at sales@inceptionlabs.ai.
Check out our tech report for more information about our dLLMs.